2024. 2. 8. 19:45ㆍDL Life
개념 설명
Dataset 의 Distribution 이 Skewed 되어 있는 (한쪽으로 쏠려있는) 상태
- Head Class : 데이터셋에서 dominant sample 수를 가지고 있는 class
- Tail Class : 데이터셋에서 scarce sample 수를 가지고 있는 class

특히 Class Imbalance 의 Imbalance Ratio 가 극심한 특수한 경우에 LTD 를 갖는다고 표현
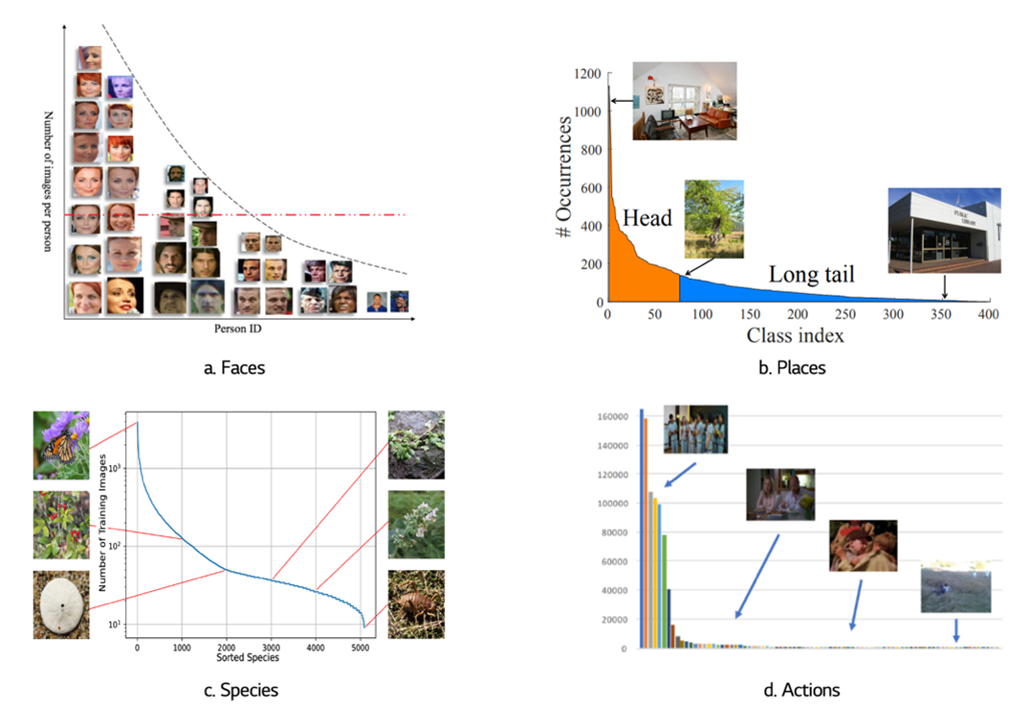
대표적으로 불량 감지, 질병 진단, 자율 주행 차 사고 감지, 사이버 보안 등의 분야에서 관찰가능
문제가 되는 이유
- 모델이 다양한 Task 에서 좋은 성능을 내기 위해서는 각 Class 의 Representation 을 잘 학습해야하는데, 모델이 head-class 에 편향되게 학습하여 tail-class 에 대해서 심각한 성능저하가 발생
해결 방법
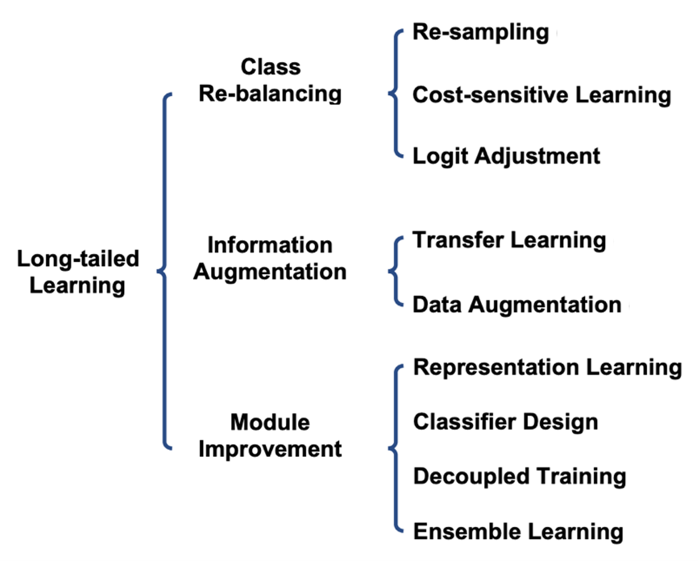
1. Class Re-balancing
Re-sampling
- data-level의 접근법, 지난 몇십년동안 가장 널리 사용되었던 방법
- Under-Sampling
Head class 의 데이터 개수를 Tail class 의 데이터 개수와 맞추는 방식 (Head → Tail)
Head class sample 각각이 중요한 정보를 가지고 있을 경우 정보 손실 및 Underfitting 가능성 상승
→ One-side selection, Wilson’s Editing 과 같은 방법 제안 - Over-Sampling
Tail class 의 데이터를 랜덤으로 복제하여 Head class 의 데이터 개수와 맞추는 방식 (Tail → Head)
Tail class 의 Robust, Generalizable 한 Feature 추출에는 한계 (왜? tail class 자체가 적다보니 다양성이 적어서?) + Overfitting 가능성 상승
→ Synthetic Minority Over-sampling Technique (SMOTE) 를 활용한 다양한 방법 제시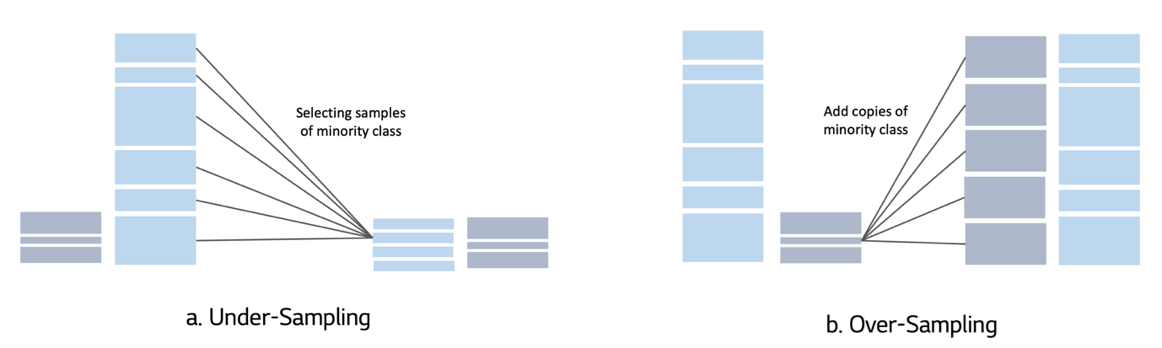
- Scheme-oriented re-sampling
- metric learning 이나 Ensemble learning 등 long-tailed learning 을 위한 Training methods
- [꼼꼼한 논문 설명] Imbalanced Continual Learning with Partitioning Reservoir Sampling (ECCV 2020) - YouTube
Cost-sensitive Learning
- Training 단계에서 각 class 별 loss 값을 다르게 주어 Re-balance 하는 algorithm-level 접근법
- Loss 설계 시, head-class에 penalty를 주거나, tail-class에 weight를 더 주는 방식으로 일반화 성능 향상
- Re-writing, Re-margining 등이 있음

- 미리 Loss weight 를 정하는 것 이외에도 데이터로부터 weight 가 학습될 수 있음
- Distribution Alignment (DisAlign) : 예측분포와 주어진 균형 reference 분포가 있으면 이들 사이의 kl-divergence값을 최소화하는 함수 사용
Logit Adjustment
- 고전적인 Idea, 클래스 불균형 문제에서 상대적으로 큰 Margin 을 얻는 방법
- Logit : 최종 레이어가 내놓는 값, 어떤 클래스인지 예측하는 확률?
Summary
- Class Re-balancing 기법들은 단순하지만 괜찮은 성능을 보임
- Head class 성능이 떨어진다는 단점이 존재 + 정보가 부족하다는 문제를 근본적으로 해결하지 못함
2. Information Augmentation
Transfer Learning
- source 도메인(e.g. 데이터셋, task, 클래스…)으로부터 정보를 전이하여 타겟 도메인에 대한 모델 훈련을 강화
Head-to-Tail Knowledge Transfer Learning
LTD에서의 Transfer Learning에는 head-class의 정보를 tail-class로 전이하여 모델의 성능을 증대하는 Head-to-tail knowledge Transfer Learning이 있습니다.
Feature Transfer Learning (FTL)은 tail-class 내의 variance가 head-class에 비해 훨씬 작아 decision boundary가 편향되게 형성되는 것을 개선하기 위해, head-class의 variance 정보에 기반한 tail-class feature augmentation을 하도록 합니다. → tail-class 샘플들의 클래스 내부의 variance가 더 작아 특징공간과 결정경계가 편향되어 있는 문제를 head class의 클래스 내부의 분산을 활용하여 tail-class에 대한 성능을 높여 tail-class 특징들이 더 높은 클래스 내부 분산을 가지게하여 해결
Online Feature Augmentation (OFA)는 class activation map에 기반하여 class-specific feature와 class-agnostic feature를 추출합니다. 그다음, tail-class specific feature와 head-class agnostic feature에 기반하여 tail-class sample을 증강합니다.
Rare Class Sample Generator (RSG)는 각 class 별 feature center를 추정한 후 head-class sample feature와 가장 가까운 intra-class feature center 간 feature displacement에 기반하여 tail-class feature를 보강합니다.
→ 이 부분을 제대로 이해하지는 못해서 일단 Reference 자료 삽입
Knowledge Distilation

미리 학습시킨 Teacher network 의 출력을 내가 실제로 사용하고자 하는 작은 모델인 Student network 가 모방하여 학습
Data Augmentation
모델 훈련 시 데이터셋의 양과 질을 향상시키기 위한 증강 기술
- transfer-based augmentation : Major2minor 방식을 에로 드는데 이는 적대적 공격과 유사한 방법
- conventional(non-transfer) augmentation : 기존의 데이터 증강기법을 개선하거나 설계
Summary
→ 기존의 Re-balancing 방식과 달리 head class 성능을 희생시키지 않기 떄문에 더 자세히 연구할 가치가 있다.
→ head class 를 더 많이 증강할 수 밖에 없다는 기본적인 문제점은 아직 해결하지 못하였다
3. Module Improvement
Representation Learning
- Metric Learning : input data 간 거리를 학습하는 것을 의미 / 데이터간의 유사도를 수치화
→ 객체간 유사성/비유사성에 대한 task specific 거리함수 (distance metric)를 설계하는 것이 목표 - Contrastive Learning : 각 Class 를 명확하게 보여줄 수 있도록 학습하는 방식
- etc …
Classifier Design
- 다양한 유형의 Classifier 를 설계

Decoupling Training
- Learning Procedure : Representation Learning + Classfier Training 으로 분리 → 2-stage 학습방식 제안
- 표현학습을 위한 여러 Sampling strategy 를 평가 → Trained feature extractor 로 Classifer training scheme 평가
[!note] 관찰결과
- Random sampling 이 의외로 docoupling 방식에서는 best
- Clasifer 를 Re-adjusting 하는 것만으로도 상당한 성능 향상
Ensemble Learning

데이터셋을 다양한 방식으로 샘플링하여 모델들을 학습시키고 ensemble
다양한 모델을 같은 데이터셋으로 학습시키고 Ensemble 등의 방식을 사용
- Ally complementary experts(ACE) 여러 균형 그룹으로 나누는 대신, 여러 skill-diverse 하위 집합으로 나누는데, 한 집합은 모든 클래스를 포함하고, 하나는 middle, tail 클래스만 포함하고, 다른 하나는 tail 클래스만 포함하는 식으로 학습을 진행, 여러 expert들로 이 다양한 클래스 하위집합을 훈련시는데 이 때, 다양한 하위집합이 서로 다른 샘플 수를 가지고 있다는 것을 고려하여, 다양하게 학습률을 조정하면서 학습을 진행
Summary
- Network module 을 개선하여 문제를 해결하고자 한다
- 기존 algorithm, data 적인 측면으로 해결하려고 한 것과는 조금 다른 관점이라고 할 수 있다
- Data augmentation 과 상호보완적이기 떄문에 같이 사용하면 더 나은 효과를 얻을 수 있다
평가방식
차후 추가 예정
(https://haystar.tistory.com/82) 참고
Reference
LG Research - Long-Tail Distribution
Long-tail Survey 관련 글
https://light-tree.tistory.com/196 [All about:티스토리]
Link
“이 글은 Obsidian 에서 작성되어 업로드 되었습니다”
'DL Life' 카테고리의 다른 글
| Dacon 도배 하자 질의 응답 처리 경진대회 (4)QLoRA + 4bit quantization + LDCC-SOLAR-10.7B(≈9GB vram used) 코드 테스트 (0) | 2024.02.20 |
|---|---|
| Dacon 도배 하자 질의 응답 처리 경진대회 (3) Ko-SOLAR 모델 테스트 및 Data Parallel (0) | 2024.02.20 |
| Dacon 도배 하자 질의 응답 처리 경진대회 (2) 임베딩 모델 및 베이스라인 코드 (0) | 2024.02.19 |
| Dacon 도배 하자 질의 응답 처리 경진대회 (1) 대회 탐색 (0) | 2024.02.12 |
| Contrastive Chain of Thought (1) | 2023.12.01 |