2024. 6. 24. 00:02ㆍ카테고리 없음
Agentic Design Pattern
LLM 에게 한번의 Zero-shot 으로 사용
1. 수정 없이, -> Reflection
2. 외부자료 없이, -> Tool Use
3.백지 상태에서, -> Planning
4.의견을 나눌 사람 없는 상황에서 -> Multi Agent
높은 퀄리티를 기대하는 것이다
이렇게 부탁하면 어떨까? → Agent Workflow
글의 아웃라인을 작성하세요
1. 글에서 필요한 정보가 무엇인지, 어디서 찾을지 결정하고 정보를 수집하세요
2. 초안을 작성하세요
3. 초안을 다시 읽고 근거 없는 주장이나 관련 없는 정보를 찾으세요
4. 초안에서 발견된 부족한 부분들을 수정하세요
5. 관련 전문가에게 검토를 받으세요
6. 이를 반복하세요

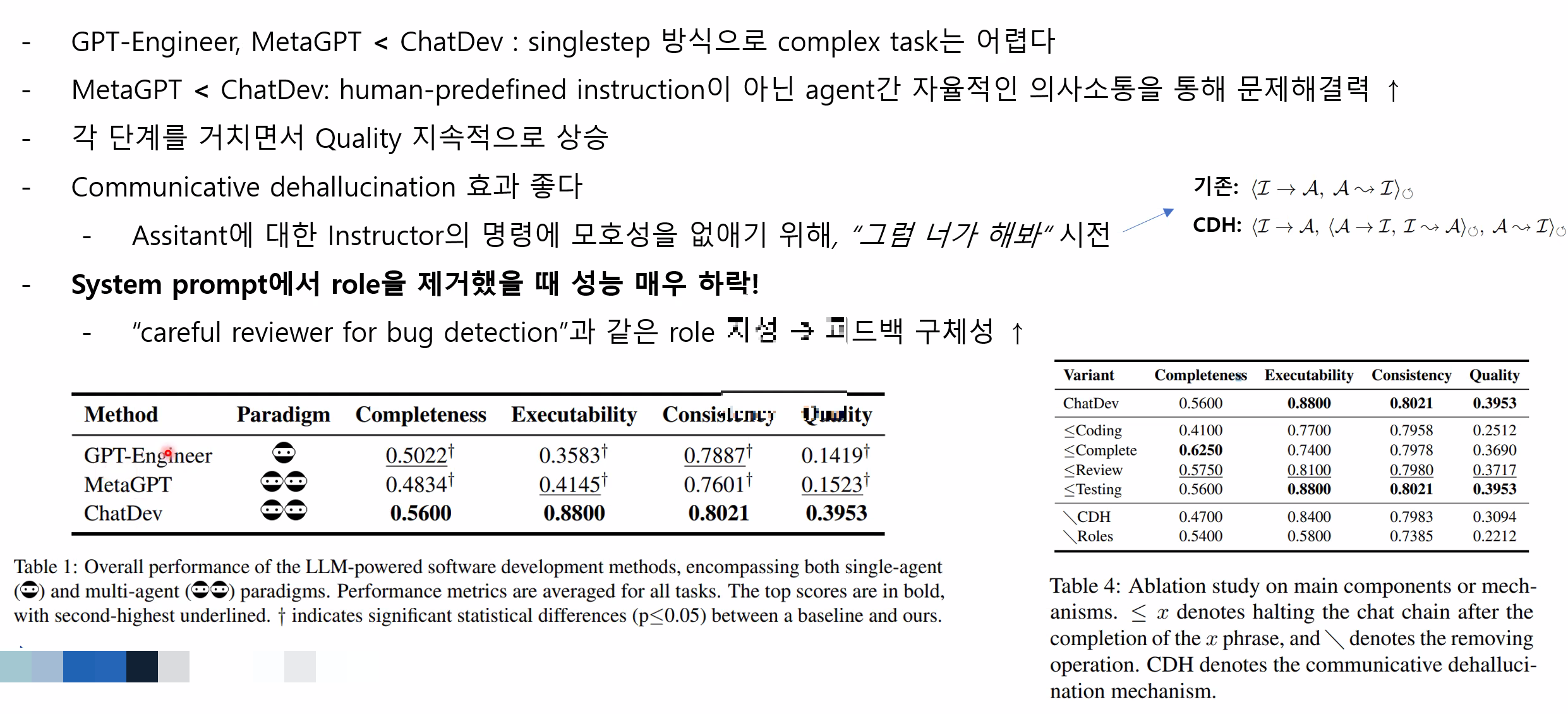
세대 업그레이드 보다 에이전트 워크플로우를 적용하는 것의 성능이 월등히 좋다

1.Reflection
참고용 논문
"Self-Refine: Iterative Refinement with Self-Feedback," (NeurIPS 2024)
"Reflexion: Language Agents with Verbal Reinforcement Learning," (NeurIPS 2023)
"CRITIC: Large Language Models Can Self-Correct with Tool-Interactive Critiquing." (ICLR 2024)
LLM 이 자신의 출력을 스스로 검토하여 개선하도록 함
ChatGPT 사용 중 만족스럽지 않은 답변에 대해 피드백을 주어 답변을 개선해 본 적 있을 것
모델 출력에 대해 피드백을 주는 것을 자동화 > 자동으로 출력 결과를 개선
Image.png
+ Tool Use: 작성된 코드를 외부 interpreter를 통해 실행하여 결과 확인하는 피드백 시스템 구현
+ Multi-agent: 출력을 잘 생성하는 agent와 출력을 잘 검토하는 agent를 별도로 구현
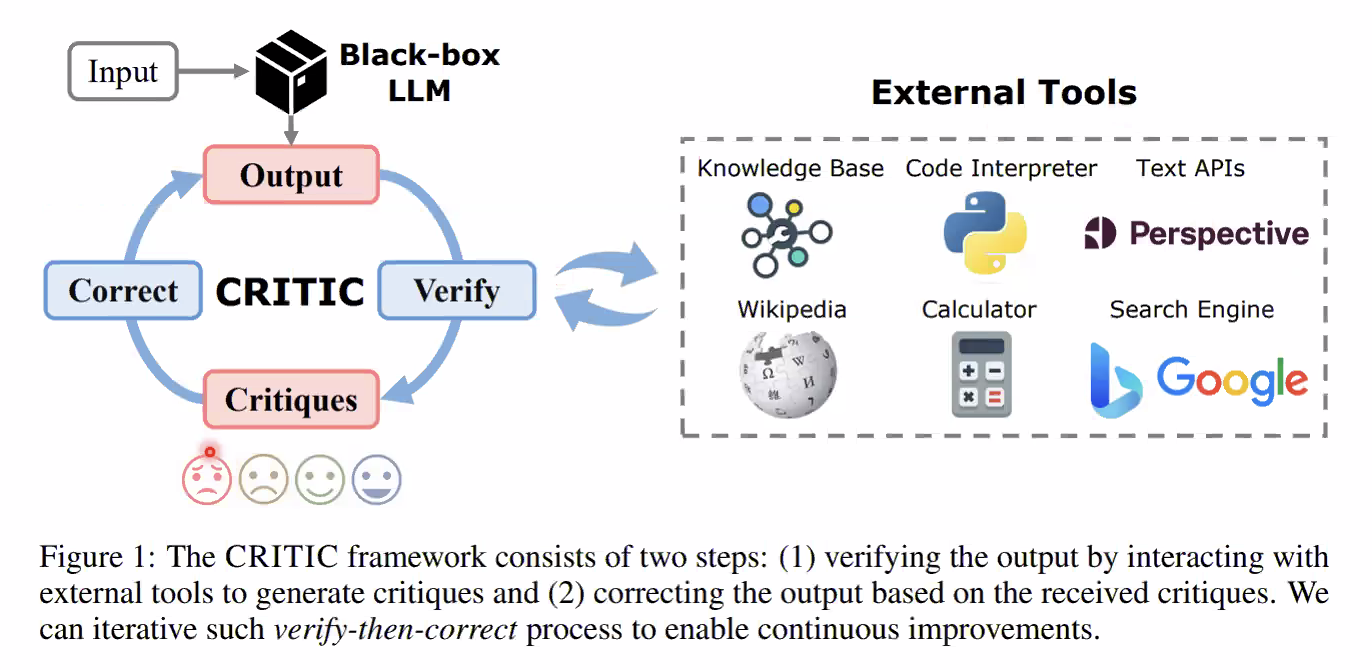
LLM의 output을 1) 검증하여 비평(critiques)을 생성하고, 2) 이에 기반한 output 수정. 이를 반복
검증 시 외부 tool 을 사용 (To Use)
모든 과정은 few-shot demonstration을 통해 별도 데이터 생성 없이 바로 진행
Free form QA, mathmatical program synthesis, toxicity reduction 태스크에 대해 실험 수행
In-context Learning 할 수 있게 더 보여줌


CRITIC 과정
- Initial answer (CoT)
- Model-generated query
- API call result
- Corrected answer
[ : 한 번의 inference를 위한 input → 반복적으로 이전 Answer 를 넣음 여러번 [ 마다 Iteration 을 반복해서 개선을 해나가는 것
- Corrected answer가 다음 iteration의 initial answer로 입력, 이를 반복
- 위에서 이런식으로 검증을 하라고 Few-shot 을 보여줌 1.Plausibility, 2.Truthfulness
Free-form QA
- 모든 데이터셋에서 CoT 대비 높은 성능 향상 (3번의 correction)
- 성능이 높은 LLM에서 더 잘 작동 (ChatGPT)
- 검증에서 외부 Tool 활용이 중요함. LLM이 스스로 검증 잘 못함
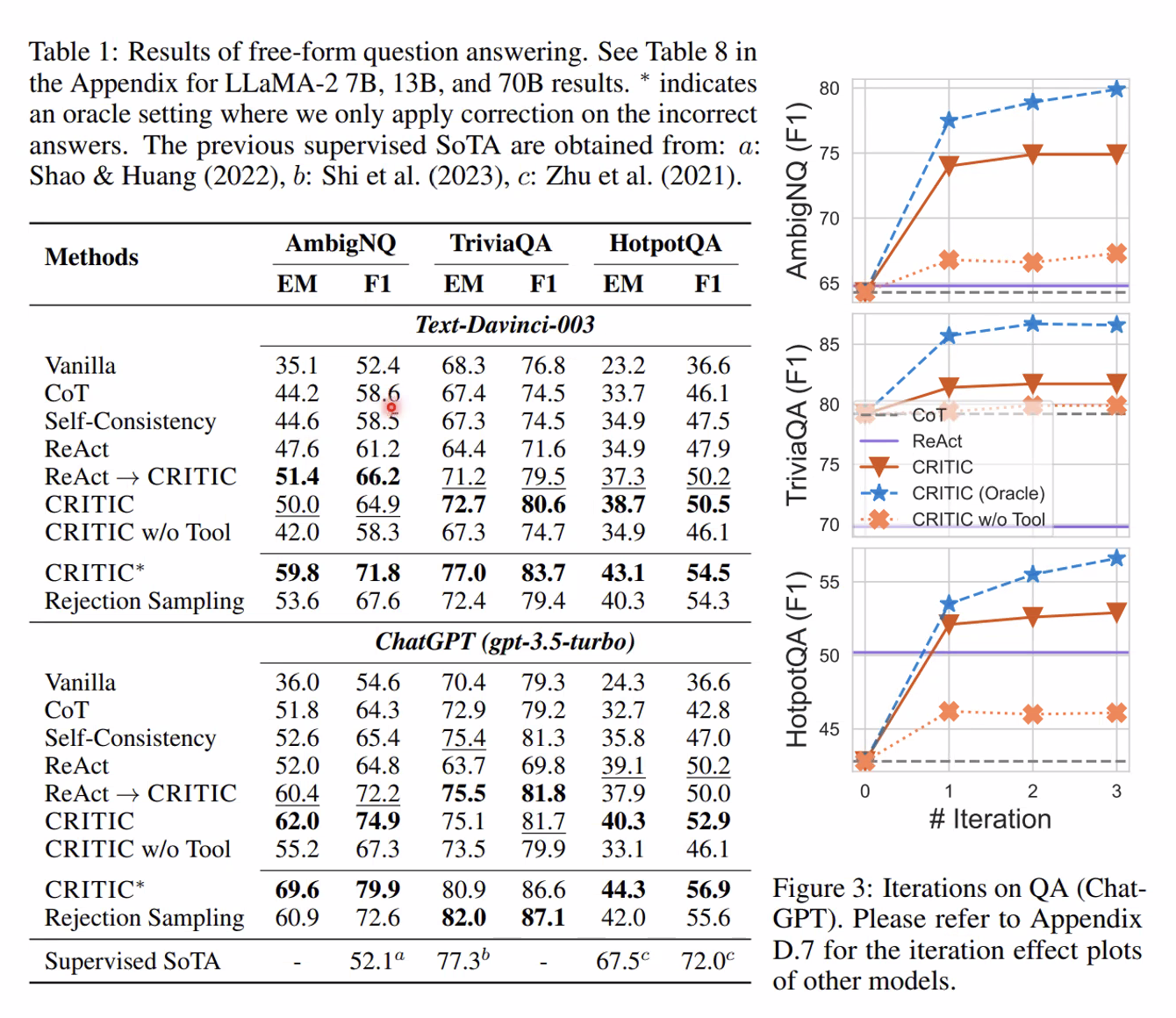
Text-davinci 보다 GPT 가 더 좋은 개선성능 = 성능이 좋은 모델일수록 이런 개선 방법의 효과가 더 뛰어나다는 것을 알 수 있었다.
2. Tool Use
"Gorilla: Large Language Model Connected with Massive APls," (arXiv 2023)
"MM-REACT: Prompting ChatGPT for Multimodal Reasoning and Action," (arXiv 2023)
"Efficient Tool Use with Chain-of-Abstraction Reasoning," (arXiv 2024)
Tool Use와 Reflection은 상당히 안정적으로 내 연구들에 적용하고 있는 방법론이다. - Andrew Ng
- CoA reasoning
- Finetuning 데이터 생성
- Full finetuning, batch 8, 200~500 step 정도 학습 → LoRA?
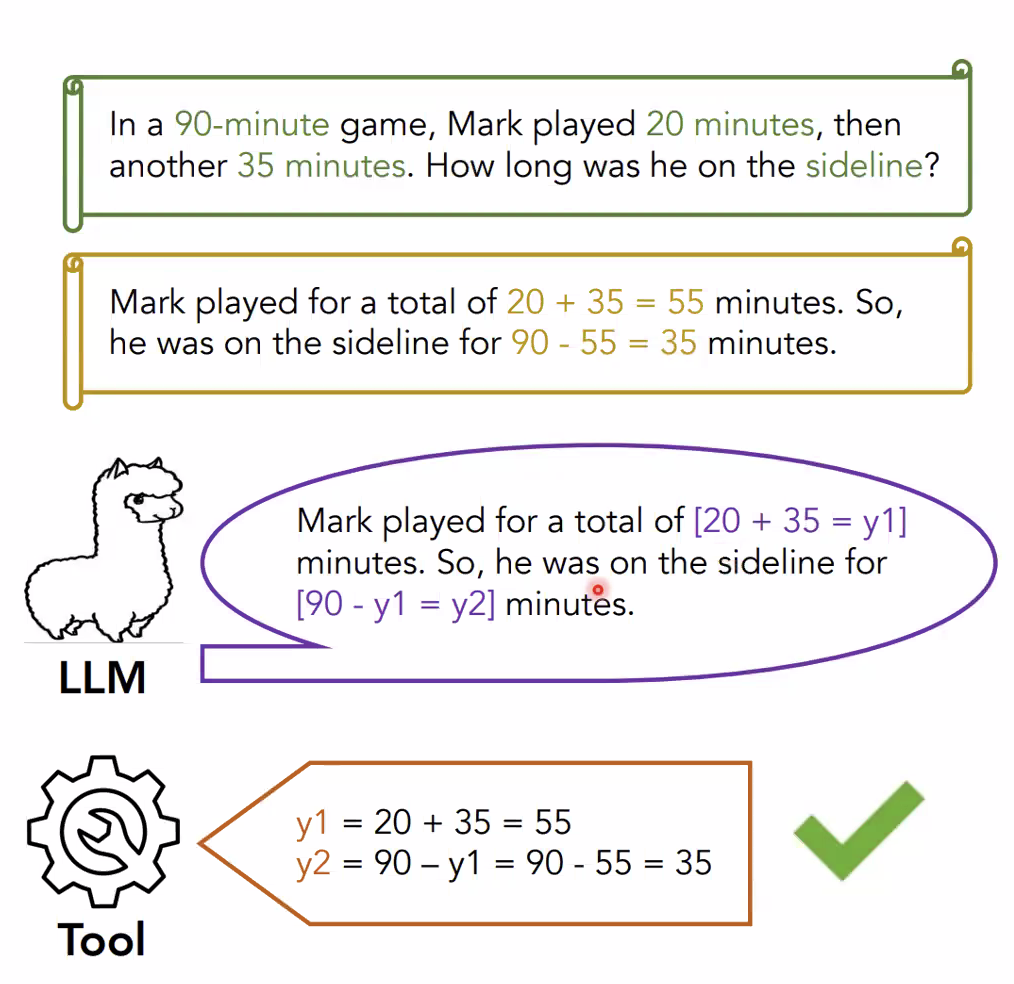
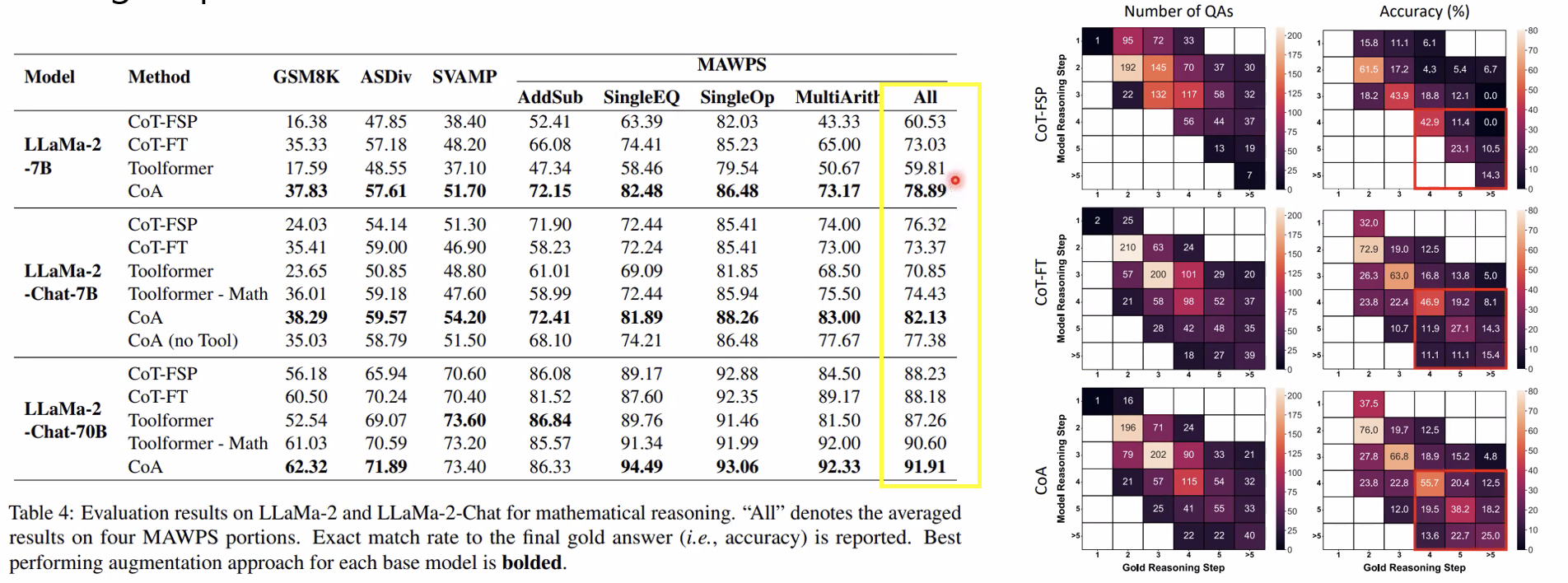
- Few-shot CoT(CoT-FSP), Finetuned CoT(CoT-FT, CoA no Tool) 보다 높은 성능 → Tool 사용의 효과
- Indomain(GSM8K, ASDiv)보다 outdomain에서 CoT-FT와의 성능차이 두드러짐 → General reasoning strategy 학습으로 인한 Robustness
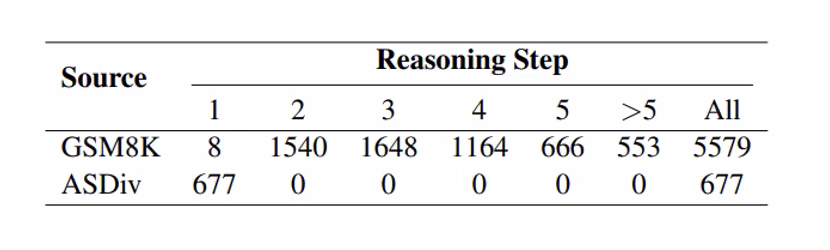
- 요구되는 reasoning step 수가 많을 수록 CoT 대비 높은 성능
3. Planning
"Chain-of-Thought Prompting Elicits Reasoning in Large Language Models," (NeurIPS 2022)
"HuggingGPT: Solving Al Tasks with ChatGPT and its Friends in Hugging Face," (NeurIPS 2024)
"Understanding the planning of LLM agents: A survey," (arXiv 2024)
- LLM이 하나의 목표 달성을 위해 여러 단계의 계획을 세워 실행하도록 함
- 하나의 복잡한 태스크는 단순한 여러 서브태스크로 분할될 수 있음.
- 단순하고 고정적인 태스크에서는 plan을 사람이 미리 정해놓거나, reflection을 사용하여 개선할 수 있음
- But, plan을 일일이 정의할 수 없는 복잡한 태스크에서 LLM이 동적으로 이를 결정하게 할 수 있음

Planning is a less mature technology, and I find it hard to predict in advance what it will do. But the field continues to evolve rapidly, and I'm confident that Planning abilities will improve quickly.
- LLM이 Hugging Face에서 필요한 모델을 선택하고 각각의 결과를 취합하여 응답 생성
- 다양한 input, output 유형: vision, speech, language
- Hugging Face의 모델 별 description을 활용, LLM이 여러 모델 사용을 planning, scheduling, cooperation
- 3500개의 다양한 user request에 대해 정답 plan을 만들고, 모델의 planning 성능을 검증
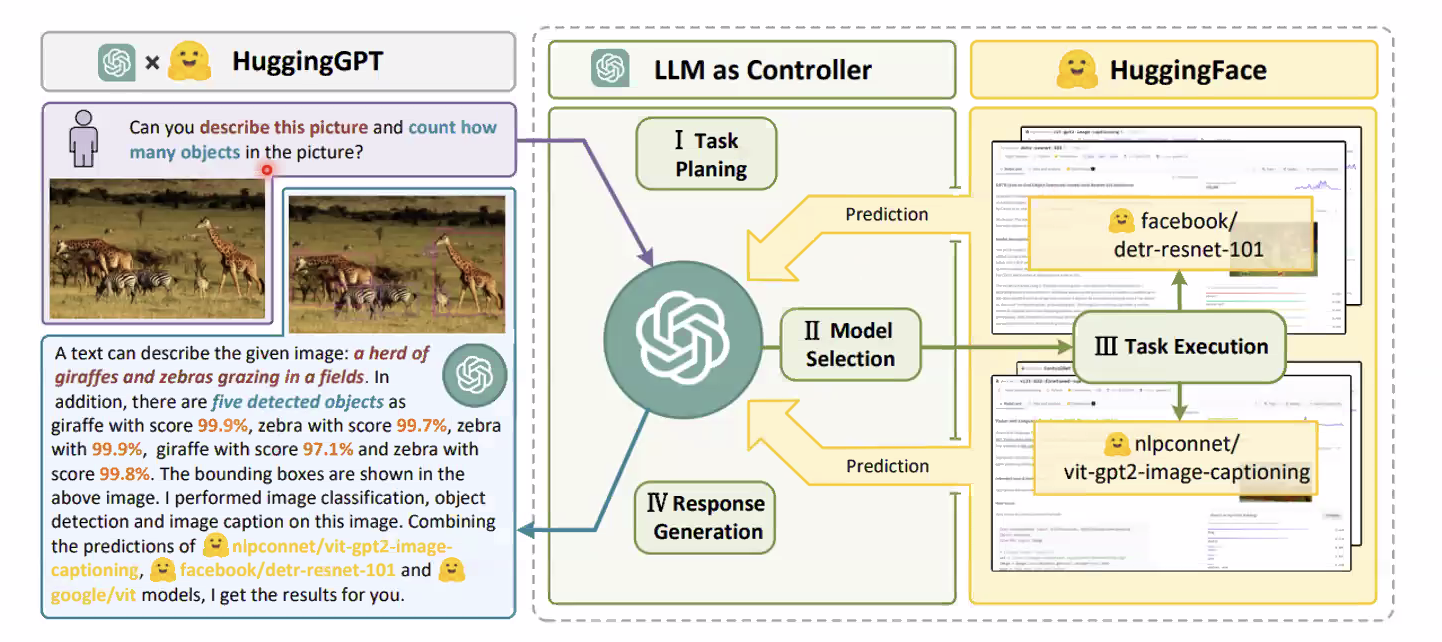
- Task Planning: LLM이 유저의 의도 파악, 해결가능한 태스크들로 세분화
- Model Selection: LLM이 모델 description을 기반으로 계획된 태스크를 해결할 수 있는 모델 선택
- Task Excution: 선택된 모델을 실행하여 그 결과를 LLM에 전달
- Response Generation: LLM이 모든 모델의 실행결과를 취합하여 최종 응답 생성

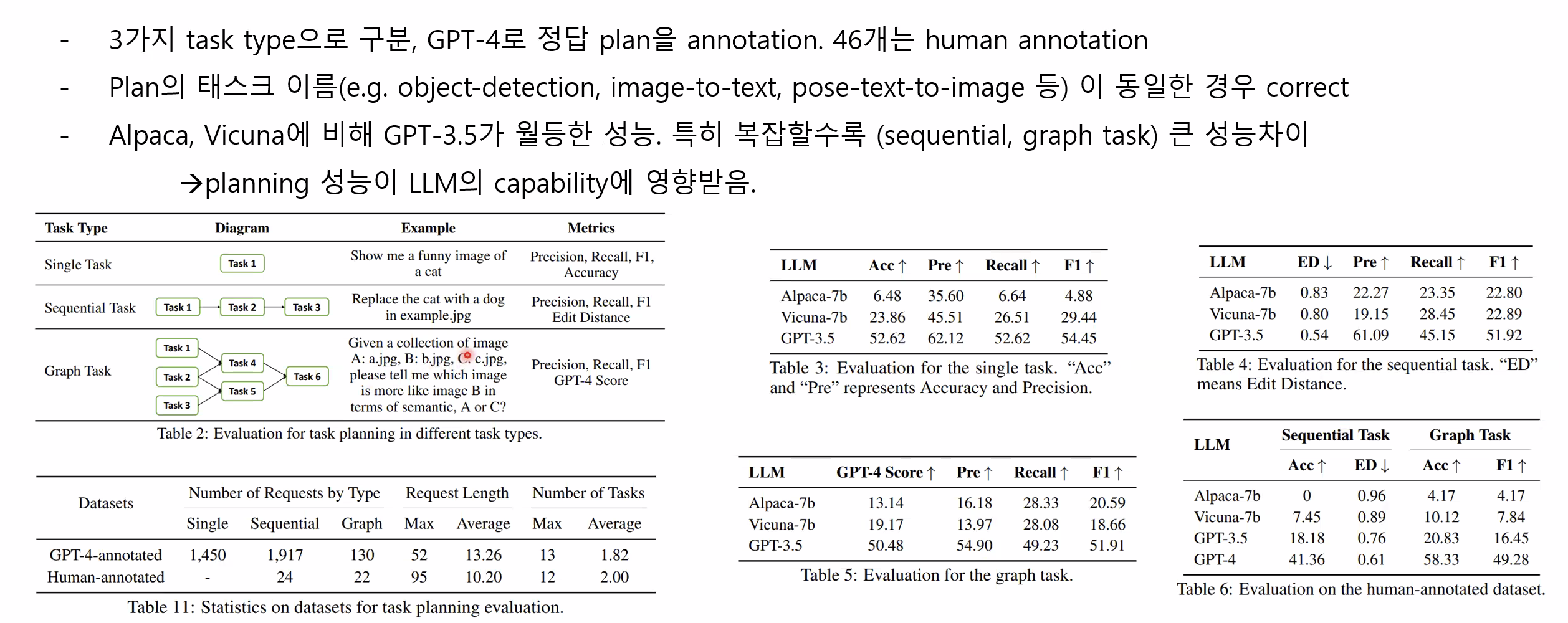
- 3가지 task type으로 구분, GPT-4로 정답 plan을 annotation. 46개는 human annotation
- plan의 태스크 이름(eg. object-detection, image-to-text, pose-text-to-image 등) 이 동일한 경우 correct
- Alpaca, Vicuna에 비해 GPT-3.5가 월등한 성능. 특히 복잡할수록 (sequential, graph task) 큰 성능차이 → planning 성능이 LM의 capability에 영향받음
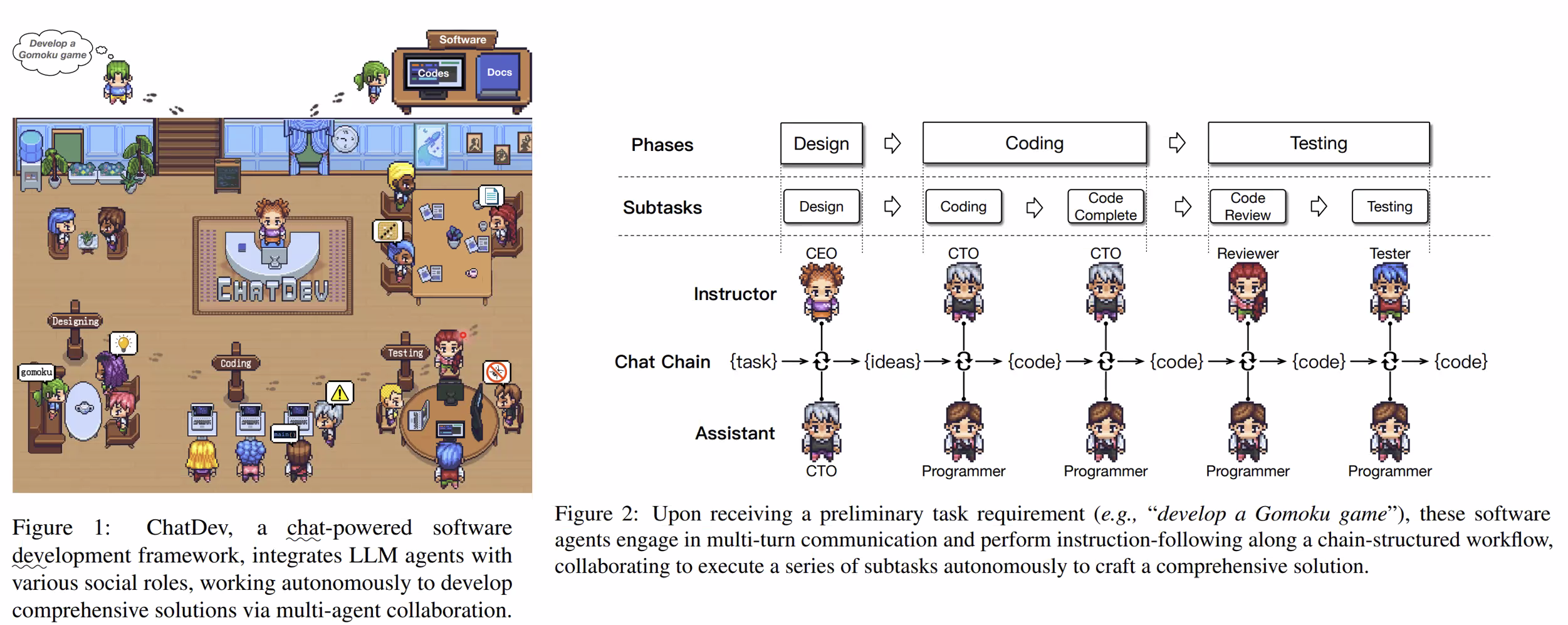
4. Multi-Agent Collaboration
"Communicative Agents for Software Development," Qian et al. (arXiv 2023)
"AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation, (arXiv 2023)
"MetaGPT: Meta Programming for a Multi-Agent Collaborative Framework," (arXiv 2023)
목표 달성을 위해 각각 다른 역할의 agent들이 협력하고 토론하여 더 나은 솔루션을 찾도록 함
하나의(또는 여러) LLM에 prompt를 통해 서로 다른 역할을 부여
- You are an expert in writing efficient code...
- You are an expert in planning a product that requires users' needs...
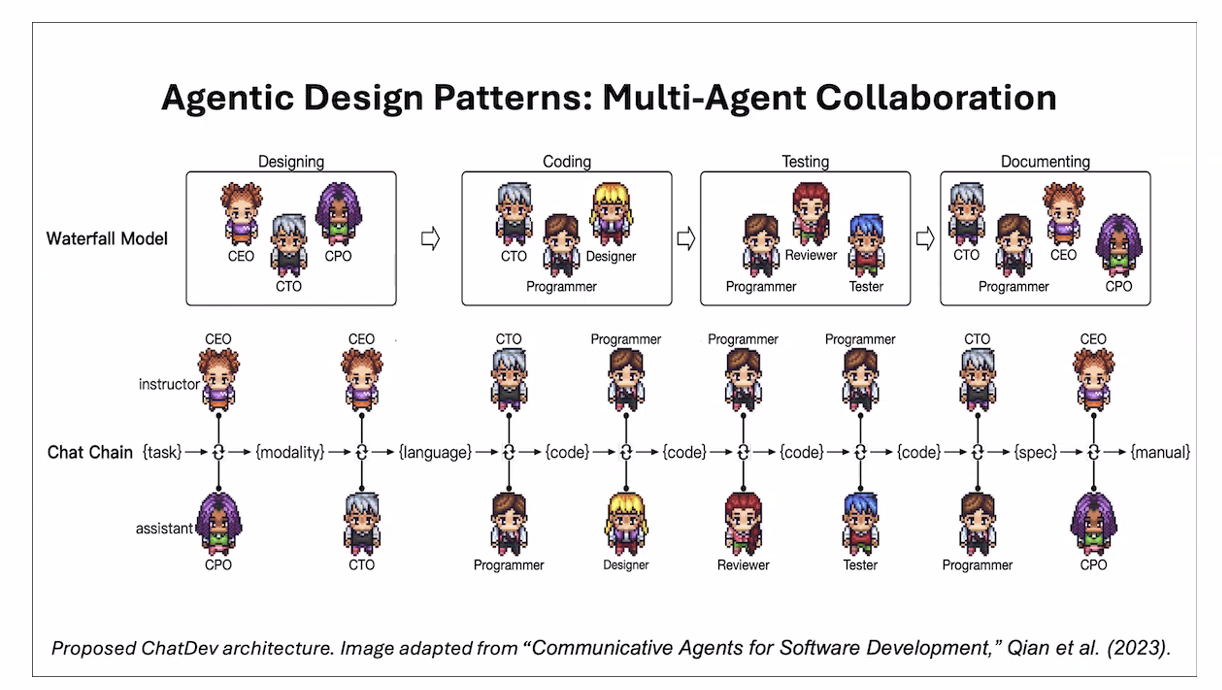
하나의 LLM에 multiple call을 할 뿐인데.. 왜 작동하나?
- 복잡한 태스크를 간단한 서브태스크들로 분할하게 됨.
I hope you enjoy playing with these agentic design patterns and that they produce amazing results for you!
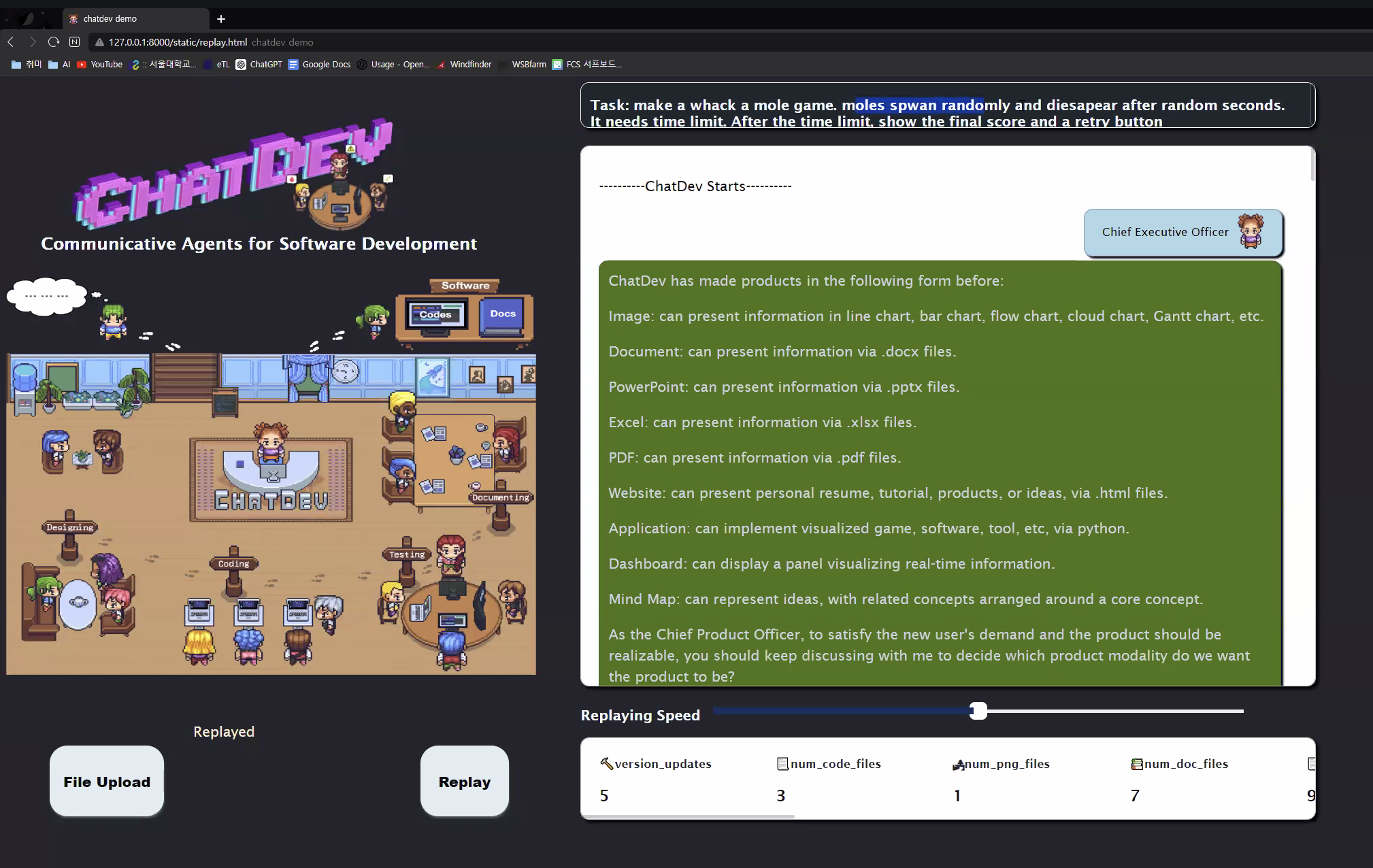
GPT-3.5 , 4, 4o 썼는데 모델이 좋을 수록 좋다 - 당연하지만
1200개의 software description set 구축
- 플랫폼: Ubuntu, Google Play, Microsoft Store, Apple Store 등
- 카테고리: Education, Work, Life, Game, Creation Evaluation metric: 완성된 software를 평가할 4개의 metric 정의
Completeness: 비워둔 곳(placeholder) 없이 완벽하게 코드를 작성하였는가?
Excutability : 바로 실행하여 작동한 비율
Consistency: requirement description과 완성된 코드의 의미적 유사성. Embedding similarity 사용
Quality: 전반적인 점수. 위 3개 항목의 곱